
BitOps: High-Performance Ternary Matrix Multiplication
Deploying quantized neural networks efficiently requires matrix multiplication kernels that can exploit the extreme sparsity and low bit-width of ternary weights. BitOps is a library purpose-built for this: it provides optimized ternary matrix multiplication across CPU and GPU backends, packing weights into just 2 bits each for a 16x memory reduction over float32.
View the BitOps GitHub Repository
The Problem
Modern neural network quantization techniques—including the ternary quantization used in TeTRA-VPR and TAT-VPR—constrain weights to {-1, 0, +1}. Standard deep learning frameworks like PyTorch have no native support for ternary arithmetic: they promote everything back to float32, wasting both memory and compute. To actually realise the theoretical gains of ternary quantization on real hardware, you need dedicated low-level kernels.
How BitOps Works
BitOps operates in two stages:
Weight Packing (
bitops.bitmatmulpack) Ternary weight matrices of shape[N, K]with values in {-1, 0, +1} are packed into a compact[N, K/4]uint8 representation, encoding four ternary values per byte. This alone cuts weight memory to ~6% of the float32 baseline.Quantized Matrix Multiplication (
bitops.bitmatmul) The packed weights are multiplied against int8 quantized activations using architecture-specific kernels. Per-row activation scales and per-channel weight scales are applied to produce float32 output, with optional bias addition.
Figure 1: Weight Memory Comparison
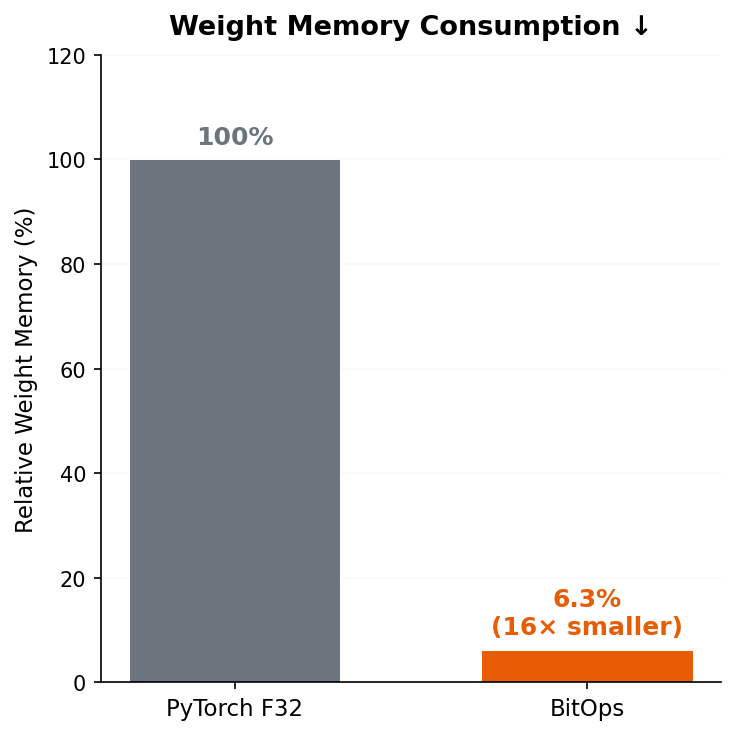 Figure 1. Memory consumption of packed ternary weights versus float32, demonstrating the 16x reduction achieved by 2-bit packing.
Figure 1. Memory consumption of packed ternary weights versus float32, demonstrating the 16x reduction achieved by 2-bit packing.
Architecture-Specific Backends
BitOps automatically selects the appropriate backend based on the tensor device:
- CPU — ARM NEON: Optimized for Apple Silicon and Arm-based processors, using NEON SIMD intrinsics for parallel ternary accumulation.
- CPU — x86 AVX2/SSE4.1: Vectorized kernels for Intel and AMD processors.
- CUDA: GPU kernels for NVIDIA hardware, automatically detected from the PyTorch installation.
The backend can also be specified explicitly:
y = bitops.bitmatmul(x, x_scale, w_packed, w_scale, b, backend=bitops.Backend.CPU)
Figure 2: CPU Benchmark
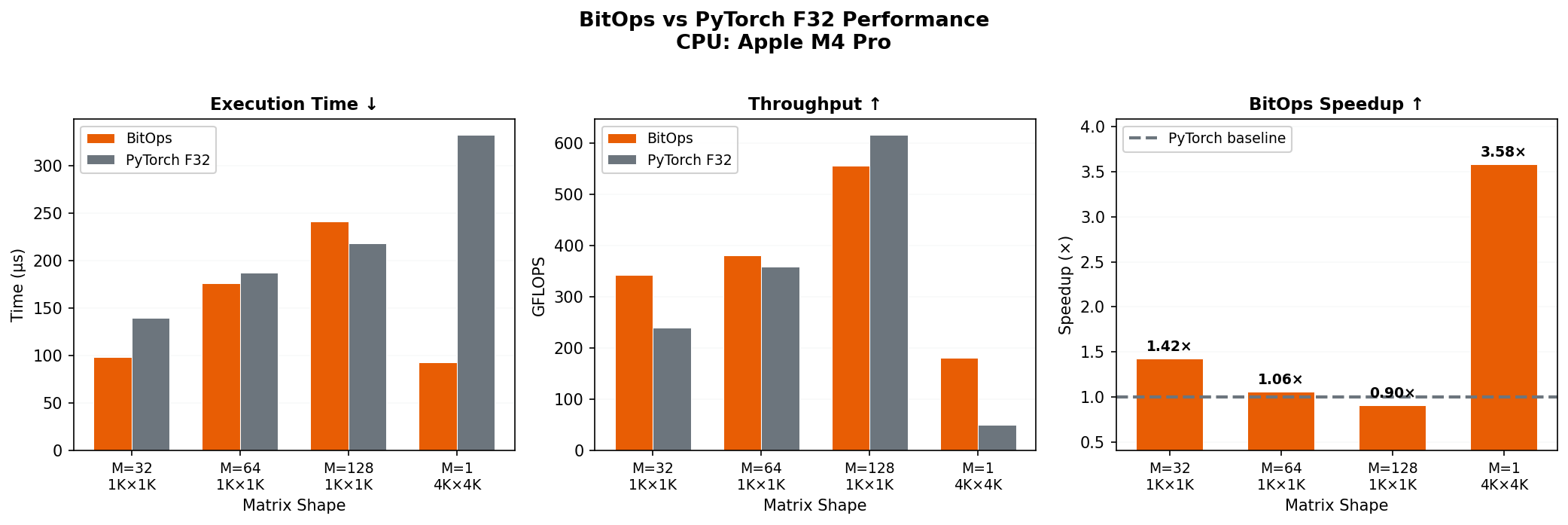 Figure 2. Runtime benchmark comparing BitOps ternary matrix multiplication against PyTorch float32 on CPU. Results vary by hardware—run
Figure 2. Runtime benchmark comparing BitOps ternary matrix multiplication against PyTorch float32 on CPU. Results vary by hardware—run python benchmark.py to generate benchmarks for your device.
Usage Example
import torch
import bitops
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
M, N, K = 32, 128, 256
# Quantized activations [M x K]
x = torch.randint(-128, 127, (M, K), dtype=torch.int8, device=device)
x_scale = torch.rand(M, dtype=torch.float32, device=device) * 0.1 + 0.01
# Ternary weights [N x K] -> packed [N x K/4]
w = torch.randint(-1, 2, (N, K), dtype=torch.int8, device=device)
w_packed = bitops.bitmatmulpack(w)
w_scale = torch.rand(N, dtype=torch.float32, device=device) * 0.1 + 0.01
# Optional bias
b = torch.randn(N, dtype=torch.float32, device=device)
# Compute: y = (x * x_scale) @ (w_packed * w_scale)^T + b
y = bitops.bitmatmul(x, x_scale, w_packed, w_scale, b)
API Reference
bitops.bitmatmul(x, x_scale, w_packed, w_scale, b=None, backend=None)
| Argument | Shape | Dtype | Description |
|---|---|---|---|
x | [M, K] | int8 | Quantized activations |
x_scale | [M] | float32 | Per-row activation scales |
w_packed | [N, K/4] | uint8 | Packed ternary weights |
w_scale | [N] | float32 | Per-channel weight scales |
b | [N] | float32 | Bias (optional) |
backend | — | Backend | CPU, CUDA, or None (auto) |
Returns: [M, N] float32 tensor.
bitops.bitmatmulpack(w, backend=None)
| Argument | Shape | Dtype | Description |
|---|---|---|---|
w | [N, K] | int8 | Ternary weights (-1, 0, 1) |
backend | — | Backend | CPU, CUDA, or None (auto) |
Returns: [N, K/4] uint8 tensor. K must be divisible by 4.
Connection to Other Work
BitOps grew out of the need for a practical runtime to back the ternary quantization research in TeTRA-VPR and TAT-VPR. Those projects demonstrate that ternary-quantized Vision Transformers can match full-precision accuracy for visual place recognition—but realising the latency and memory savings on actual hardware requires the kind of low-level kernel support that BitOps provides.
Requirements
- Python 3.7+
- PyTorch 1.8.0+
- CMake 3.18+
- C++17 compiler
License
Apache License 2.0