
TeTRA-VPR: A Ternary Transformer Approach for Compact Visual Place Recognition
Visual Place Recognition (VPR) is the process of localizing a query image by matching it against a database of geo-tagged images. In robotics and autonomous systems, this capability is vital for navigation and mapping—especially in environments where GPS or other external signals might be unreliable.
Understanding Visual Place Recognition (VPR)
Imagine a robot trying to figure out where it is by looking around and comparing what it sees with a stored set of images taken at known locations. That’s VPR in action. Traditional approaches used hand-crafted features like SIFT or SURF to detect keypoints, but modern methods harness deep learning to create robust and discriminative representations.
With the advent of Vision Transformers (ViTs), the quality of these representations has significantly improved. However, these state-of-the-art models can be large and resource-intensive, making them impractical for resource-constrained devices such as drones or mobile robots.
The TeTRA-VPR Approach: Making VPR Efficient
The paper introduces TeTRA-VPR, a method that compresses a Vision Transformer model using extreme low-bit quantization. Specifically, it applies ternary quantization to most of the transformer backbone—restricting weights to one of three possible values (-1, 0, or 1)—and further binarizes the final embedding layer. This binarization allows for highly efficient similarity searches using simple operations like XOR and bitcount.
Figure 1: TeTRA Block Diagram
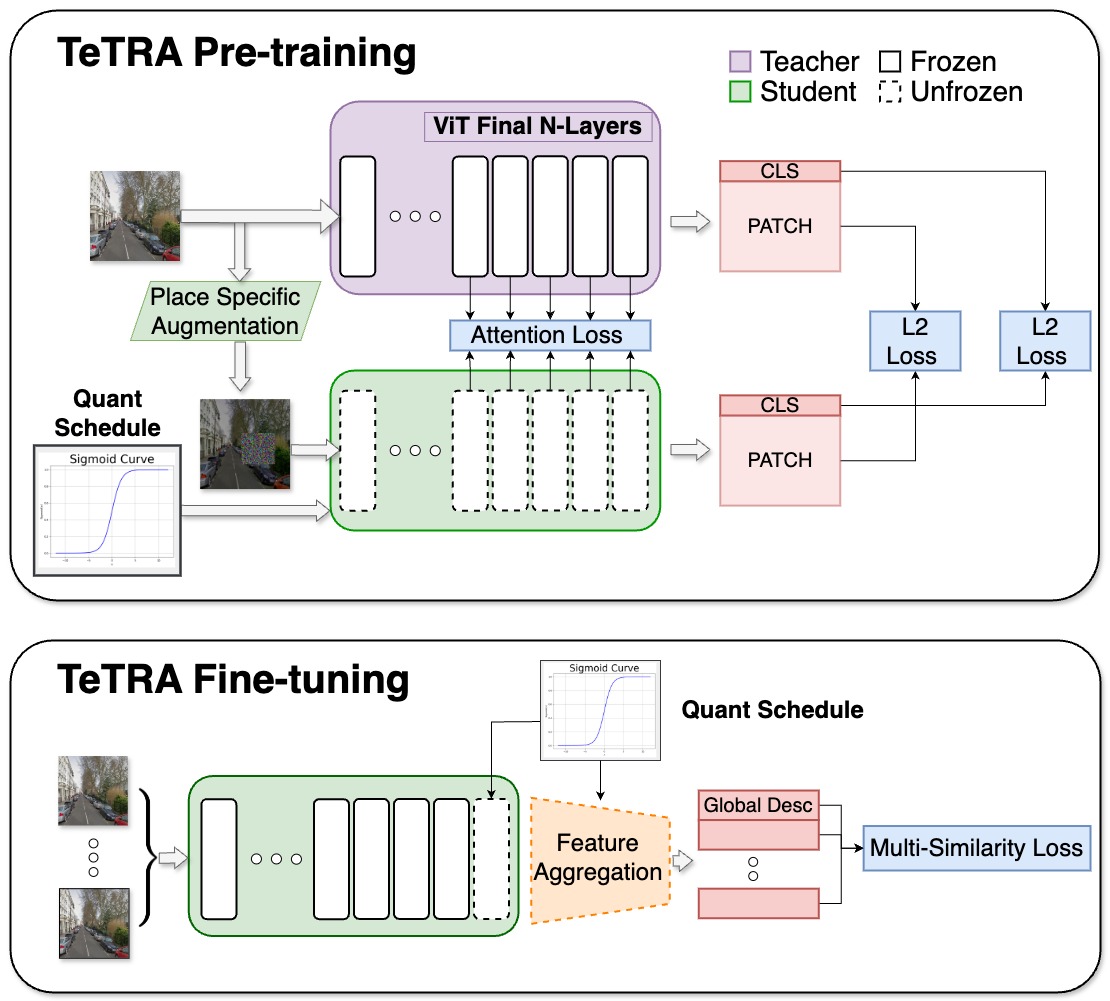 Figure 1. Block diagram illustrating the ternary and binary training pipeline.
Figure 1. Block diagram illustrating the ternary and binary training pipeline.
How TeTRA-VPR Works
Pre-training with Progressive Quantization and Distillation
The model is gradually transitioned from full-precision training to low-bit (ternary) quantization, minimizing instability by slowly introducing the quantization constraints. A powerful “teacher” model guides the “student” via knowledge distillation, helping preserve high-quality representations.Fine-tuning for VPR
After pre-training, the model is fine-tuned using supervised contrastive learning on a place-recognition dataset. Most of the transformer layers are frozen while an aggregation module is trained on top of the extracted features. The final embeddings are binarized, enabling fast similarity searches.
This careful combination of ternary quantization, binary embeddings, and progressive distillation yields a model that achieves comparable—and in some cases superior—recognition performance while using up to 69% less memory and offering 35% lower inference latency than typical convolution-based approaches.
Figure 2: Pareto-Optimal Trade-off in VPR
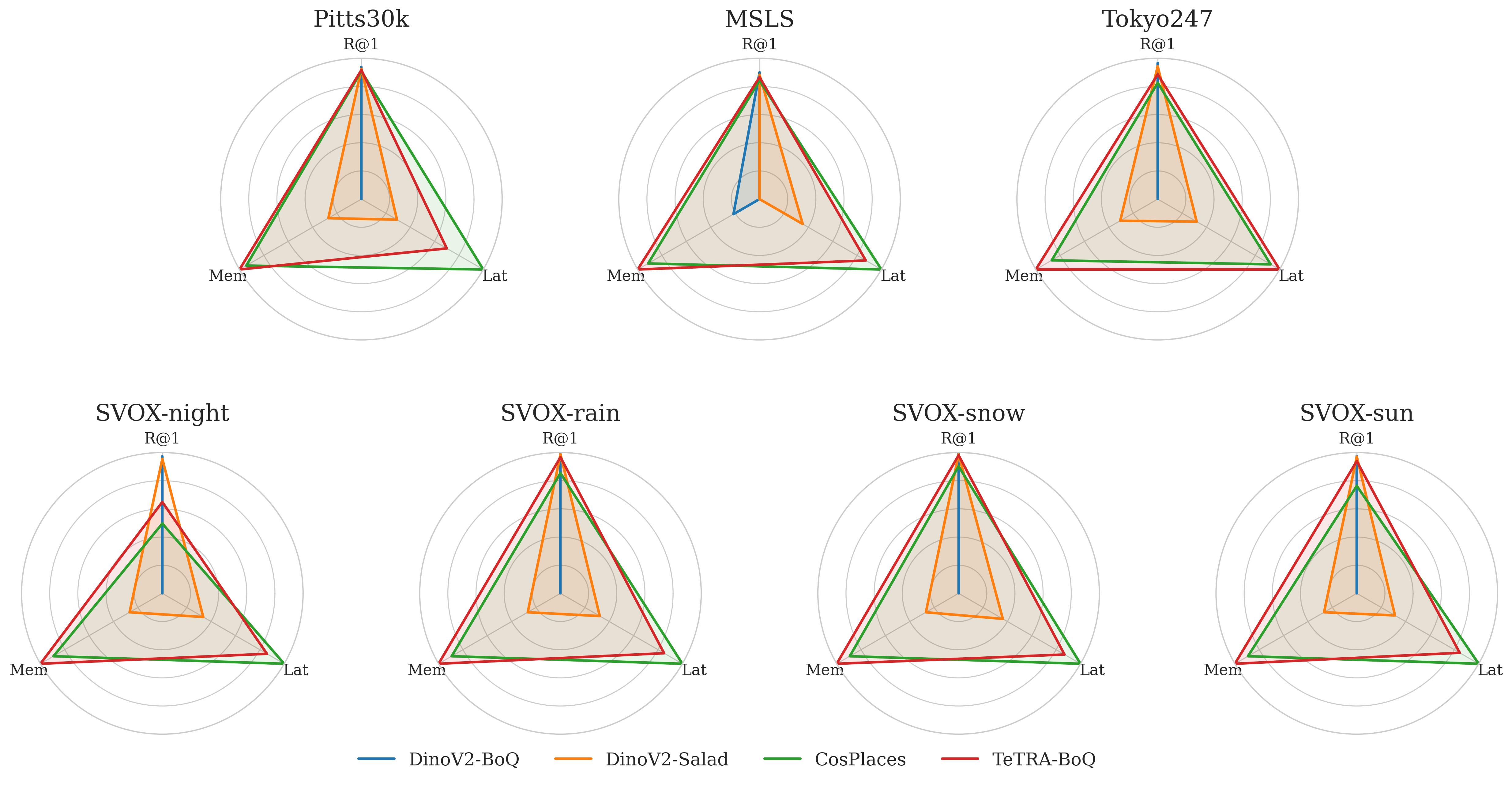 Figure 2. Radar plot comparing normalized metrics for memory usage, matching speed, and R@1 accuracy, illustrating the Pareto-optimal trade-off achieved by TeTRA-VPR.
Figure 2. Radar plot comparing normalized metrics for memory usage, matching speed, and R@1 accuracy, illustrating the Pareto-optimal trade-off achieved by TeTRA-VPR.
Experimental Highlights
Extensive experiments on standard VPR benchmarks demonstrate that TeTRA-VPR maintains high retrieval accuracy despite its significantly lower resource footprint. Whether dealing with lighting changes, occlusions, or other appearance variations, TeTRA-VPR consistently provides a strong balance between performance and efficiency—particularly crucial for platforms with tight resource constraints.
Conclusion
TeTRA-VPR proves that with a well-designed training pipeline, it is possible to compress advanced Vision Transformer models dramatically without sacrificing retrieval accuracy. This opens the door for deploying robust VPR systems on devices where memory and compute are highly limited, such as drones or small mobile robots.
As robotics and autonomous systems continue to evolve, methods like TeTRA-VPR will be integral to creating compact, efficient solutions for localization and mapping in the real world.