
RackMind: AI Agent Simulator for Data Centre Optimization
The explosion of AI workloads has pushed data centres to their thermal, power, and carbon limits. Managing these facilities is a high-stakes optimization problem: keep GPUs cool enough to avoid throttling, schedule workloads to hit SLA deadlines, minimize carbon emissions, and respond to equipment failures—all while balancing operational costs. RackMind is a high-fidelity simulator built to train and benchmark AI agents for this exact challenge, providing a safe, repeatable environment with standardized evaluation across real-world scenarios.
View the RackMind GitHub Repository
The Problem
Modern data centres are complex systems where decisions cascade: aggressive cooling wastes energy but prevents GPU throttling; delaying a training job might avoid peak carbon hours but risks SLA violations; migrating workloads away from a failing rack can trigger thermal hotspots elsewhere. Human operators struggle to balance these tradeoffs in real-time, yet there’s no standardized platform to develop and test AI-driven control policies before deploying them on live infrastructure.
Existing simulators are either too simplistic (ignoring thermal dynamics or carbon intensity), too specialized (GPU-only or cooling-only), or lack agent integration. RackMind bridges this gap: a physics-based, multi-system simulator with a clean API for agent development, automated evaluation across seven performance dimensions, and five challenging scenarios that mirror real data centre operations.
How RackMind Works
RackMind models a 128-GPU facility with realistic thermal, power, GPU, network, storage, cooling, carbon, and workload subsystems. Every 60 seconds (one simulation tick), your agent receives the full facility state and returns a list of actions—adjust cooling setpoints, migrate workloads, throttle GPUs, preempt jobs, or resolve failures.
Figure 1: Live Dashboard
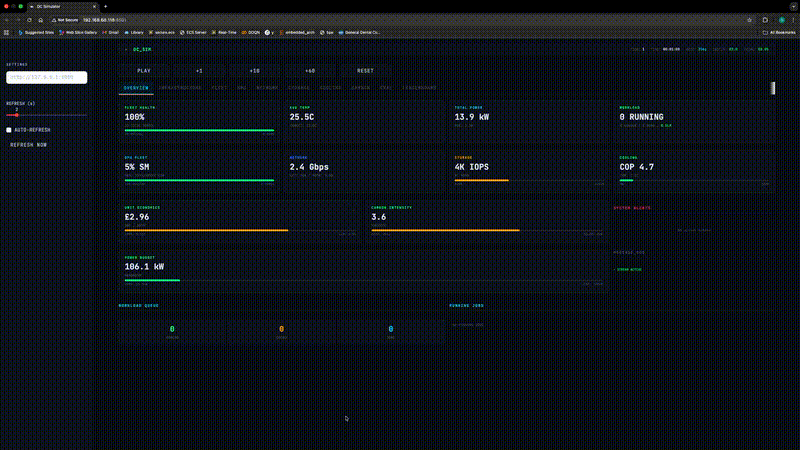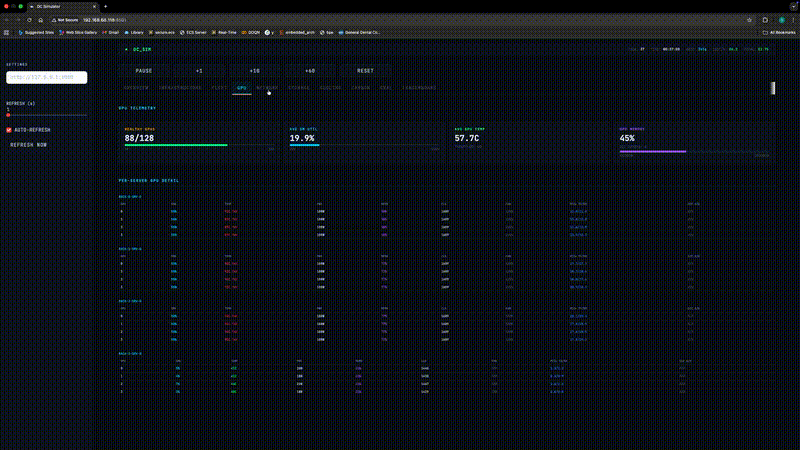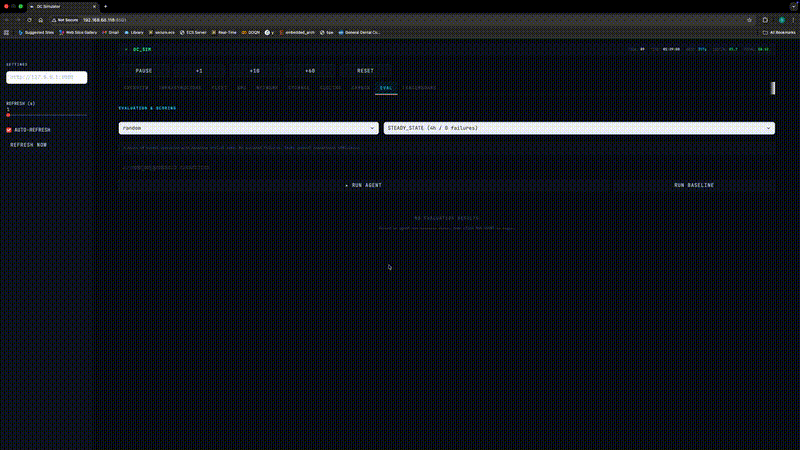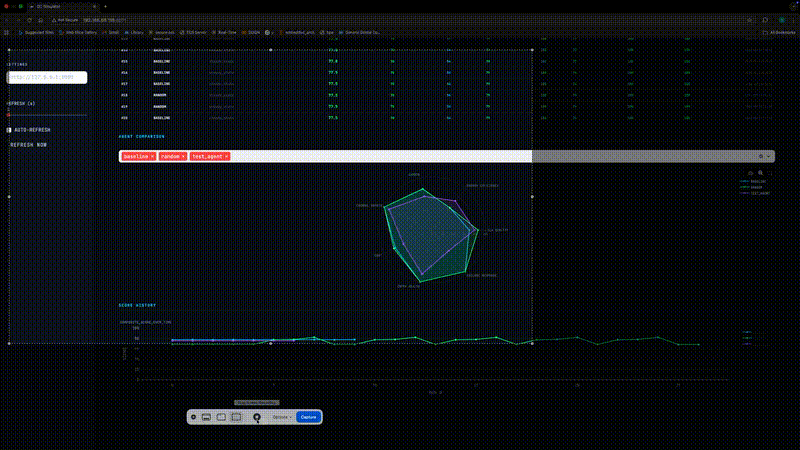 Figure 1. The real-time monitoring dashboard provides visibility across all eight facility subsystems, updated every simulation tick.
Figure 1. The real-time monitoring dashboard provides visibility across all eight facility subsystems, updated every simulation tick.
The simulator enforces physical constraints: heat recirculation between racks, non-linear GPU power curves, time-varying grid carbon intensity, and queuing latency in the network fabric. Failures inject realistic disruptions—CRAC degradation, GPU errors, network partitions—that agents must detect and recover from autonomously.
Seven-Dimensional Evaluation
Agents are scored across seven weighted dimensions, combined into a composite score (0-100):
| Dimension | Weight | What It Measures |
|---|---|---|
| SLA Quality | 25% | Job completion rate, queue wait times, deadline violations |
| Energy Efficiency | 20% | Power Usage Effectiveness (PUE), utilization-normalized consumption |
| Carbon | 15% | Emissions intensity relative to workload throughput |
| Thermal Safety | 15% | Temperature violations, GPU throttling events |
| Cost | 10% | Electricity spend per unit of work completed |
| Infrastructure Health | 10% | Equipment degradation, load balancing across racks |
| Failure Response | 5% | Mean-time-to-resolve, SLA impact during outages |
This multi-objective framework mirrors real-world operator priorities: you can’t simply minimize power at the expense of SLA violations, or cool aggressively while ignoring carbon emissions.
Five Benchmark Scenarios
| Scenario | Duration | Challenge |
|---|---|---|
steady_state | 4 hours | Baseline efficiency test under normal operations |
thermal_crisis | 2 hours | CRAC failure at t=30min—detect and migrate workloads |
carbon_valley | 24 hours | Full diurnal cycle—schedule jobs for low-carbon windows |
overload | 2 hours | 3x job arrival rate—prioritize under resource pressure |
cascade | 2 hours | Five sequential failures—multi-failure triage |
Custom scenarios can be configured from the dashboard with adjustable duration, workload arrival rates, and failure injection schedules.
Building an Agent
Agents inherit from BaseAgent and implement a single act() method that receives the facility state and returns a list of actions:
from agents.base import AgentAction, BaseAgent
class MyAgent(BaseAgent):
name = "my_agent"
def act(self, state: dict) -> list[AgentAction]:
actions = []
# Resolve active failures immediately
for failure in state.get("failures", []):
actions.append(AgentAction(
action_type="resolve_failure",
params={"failure_id": failure["failure_id"]},
))
# Cool down overheating racks
for rack in state["thermal"]["racks"]:
if rack["inlet_temp_c"] > 35:
actions.append(AgentAction(
action_type="adjust_cooling",
params={"rack_id": rack["rack_id"], "setpoint_c": 15.0},
))
# Preempt low-priority jobs if queue is backed up
if state["workload_pending"] > 10:
low_priority = [j for j in state["running_jobs"] if j["priority"] <= 1]
for job in low_priority[:1]:
actions.append(AgentAction(
action_type="preempt_job",
params={"job_id": job["job_id"]},
))
return actions
Five Action Types
adjust_cooling: Change CRAC setpoint for a rack (14-24°C)migrate_workload: Move a running job to a different rackthrottle_gpu: Cap GPU power draw (0.0-1.0 scale)preempt_job: Terminate a job to free resourcesresolve_failure: Manually resolve an active equipment failure
LLM Agent Support
RackMind’s action API maps cleanly to LLM tool-calling frameworks. Define tools that return AgentAction objects, bind them to your LLM, and parse tool invocations in the act() method. This makes RackMind compatible with LangChain, function-calling APIs, or any agent framework that supports structured actions.
What It Models
| System | Physical Details |
|---|---|
| Thermal | Hot/cold aisle configuration, heat recirculation, non-linear cooling response, time-varying ambient temperature |
| Power | Non-linear GPU power curves (idle to TDP), per-rack power distribution, dynamic PUE calculation |
| GPU | 128 H100-class GPUs: junction/HBM temps, SM utilization, memory bandwidth, clock throttling, ECC errors, NVLink topology |
| Network | Leaf-spine fabric with ToR switches, RDMA/RoCE, M/M/1 queuing latency, packet loss under congestion |
| Storage | NVMe-oF shared storage pool: IOPS, throughput, latency (Little’s Law), drive health and wear leveling |
| Cooling | CRAC units, chilled water loop, cooling tower, COP efficiency, pump power consumption |
| Carbon | UK-realistic grid carbon intensity (140-280 gCO2/kWh diurnal cycle), dynamic electricity spot pricing |
| Workload | Training/inference/batch jobs, Poisson arrivals, priority-based scheduling, SLA deadlines |
Quick Start
git clone <repo-url>
cd dc-simulator
pip install -e .
# Launch API server + dashboard
python run.py
The REST API starts at http://127.0.0.1:8000 (interactive docs at /docs). The Streamlit dashboard opens at http://localhost:8501 with live system metrics and the evaluation leaderboard.
Run a benchmark:
curl -X POST http://127.0.0.1:8000/eval/run-agent \
-H "Content-Type: application/json" \
-d '{"agent_name": "my_agent", "scenario_id": "thermal_crisis"}'
Results are automatically logged to the leaderboard and visible in the dashboard’s EVAL tab.
Architecture
dc-simulator/
├── src/
│ ├── agents/ # Your custom agents
│ │ ├── base.py # BaseAgent ABC + AgentAction
│ │ ├── random_agent.py # Example baseline
│ │ └── __init__.py # Agent registry
│ └── dc_sim/ # Simulator platform (physics models, API, scoring)
│ ├── api/ # FastAPI REST interface
│ ├── models/ # Thermal, power, GPU, network, storage, cooling
│ ├── simulator.py # Orchestration engine
│ ├── evaluation.py # 7-dimensional scoring framework
│ └── runner.py # Agent-simulator integration
├── dashboard.py # Streamlit monitoring UI
├── run.py # Single-command launcher
└── SIMULATOR_GUIDE.md # Complete API and theory reference
Agents live in src/agents/, the simulator platform lives in src/dc_sim/. You shouldn’t need to modify the simulator code—just implement your agent and register it.
Use Cases
- Reinforcement learning research: Train RL policies (PPO, SAC, DQN) on multi-objective DC control
- LLM agent benchmarking: Test function-calling agents on realistic operational tasks
- Algorithm development: Prototype thermal management, carbon-aware scheduling, or failure recovery heuristics
- Education: Teach systems optimization, control theory, or sustainable computing
Requirements
- Python 3.9+
- FastAPI, Streamlit, NumPy, PyTorch (optional for RL agents)
- See
requirements.txtfor full dependencies
License
Apache License 2.0