
TAT-VPR: Ternary Adaptive Transformer for Dynamic Visual Place Recognition
Visual Place Recognition (VPR) is the task of locating a query image by matching it against a geo-tagged database, and it forms the backbone of loop-closure in SLAM and long-term navigation. Modern Vision-Transformer descriptors offer unmatched robustness to viewpoint, seasonal and lighting changes, yet their memory and compute budgets still exceed what a micro-UAV or embedded rover can spare. TAT-VPR tackles this head-on by marrying extreme low-bit quantization with adaptive activation sparsity, giving a single model that can scale its cost up or down at run-time without retraining. :contentReference[oaicite:0]{index=0}
Understanding Visual Place Recognition (VPR)
Think of a robot flying through a forest: to know where it has been before, it compares its current camera frame with a gallery of reference images. Traditional methods relied on hand-crafted features (SIFT, ORB), while today’s best systems extract global descriptors with Vision Transformers (ViTs). These descriptors are accurate but heavy; a ViT-Base with 32-bit weights weighs in at ~87 MB and demands hundreds of billions of multiply-accumulates per second—untenable for edge devices. :contentReference[oaicite:1]{index=1}
The TAT-VPR Approach: Dynamic and Efficient VPR
TAT-VPR compresses the ViT backbone 5 × with ternary weight quantization and slashes the arithmetic workload up to 40 % via a learned top-k activation gate. Crucially, sparsity is controllable at inference time, so the same model can run in “turbo” mode on a desktop or in “battery-saver” mode on a nano-computer.
Figure 1: TAT-VPR Training Pipeline
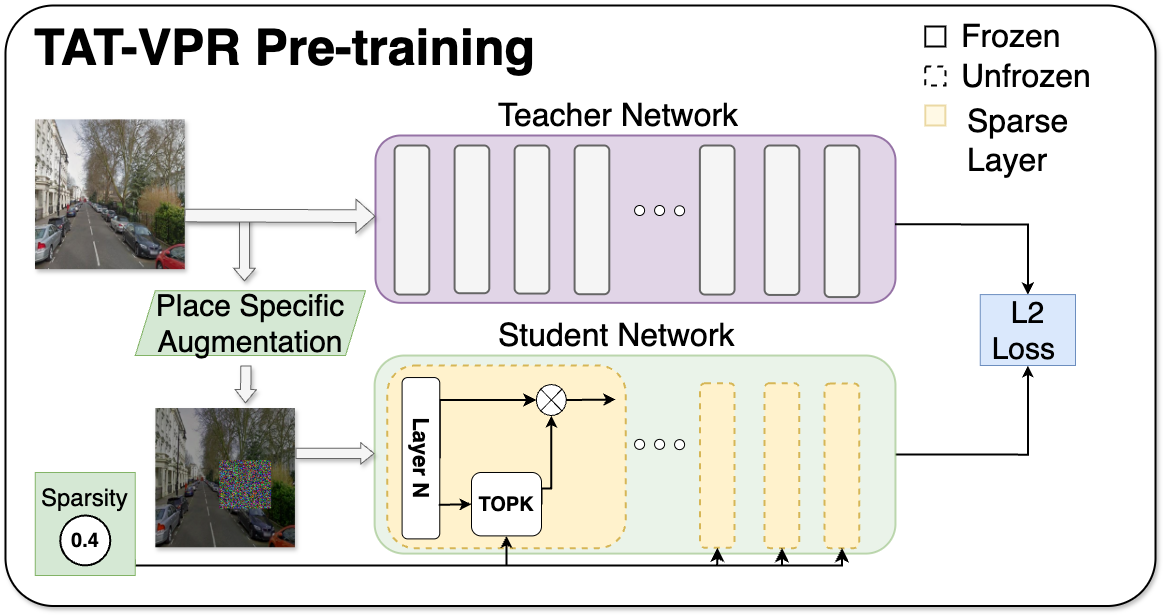
Figure 1. A frozen full-precision DINOv2-BoQ teacher supervises a sparsity-gated ternary student during progressive distillation. :contentReference[oaicite:2]{index=2}
How TAT-VPR Works
Ternary Quantized Backbone
Every weight tensor is mapped to { −1, 0, +1 }, giving an 8 × memory cut versus 32-bit floats and enabling bit-serial hardware execution. :contentReference[oaicite:3]{index=3}Adaptive Activation Sparsity
At inference, the network keeps only the top-k % highest-magnitude activation values per token. Lower k yields proportional reductions in multiply–accumulate operations, letting the robot trade a minor loss in Recall for big energy savings. :contentReference[oaicite:4]{index=4}Two-Stage Knowledge Distillation
A full-precision DINOv2-BoQ “teacher” provides token-level supervision while sparsity ramps from 10 % to 60 %. This recovers almost all of the accuracy lost to ternarisation and sparsity. :contentReference[oaicite:5]{index=5}Task-Specific Fine-Tuning
The compact backbone is frozen and fine-tuned on GSV-CITIES with multi-similarity retrieval loss. Several heads (BoQ, SALAD, MixVPR, CLS) can be swapped in, allowing designers to pick their own accuracy–speed trade-off. :contentReference[oaicite:6]{index=6}
Figure 2: Pareto Frontier of Accuracy vs. Compute
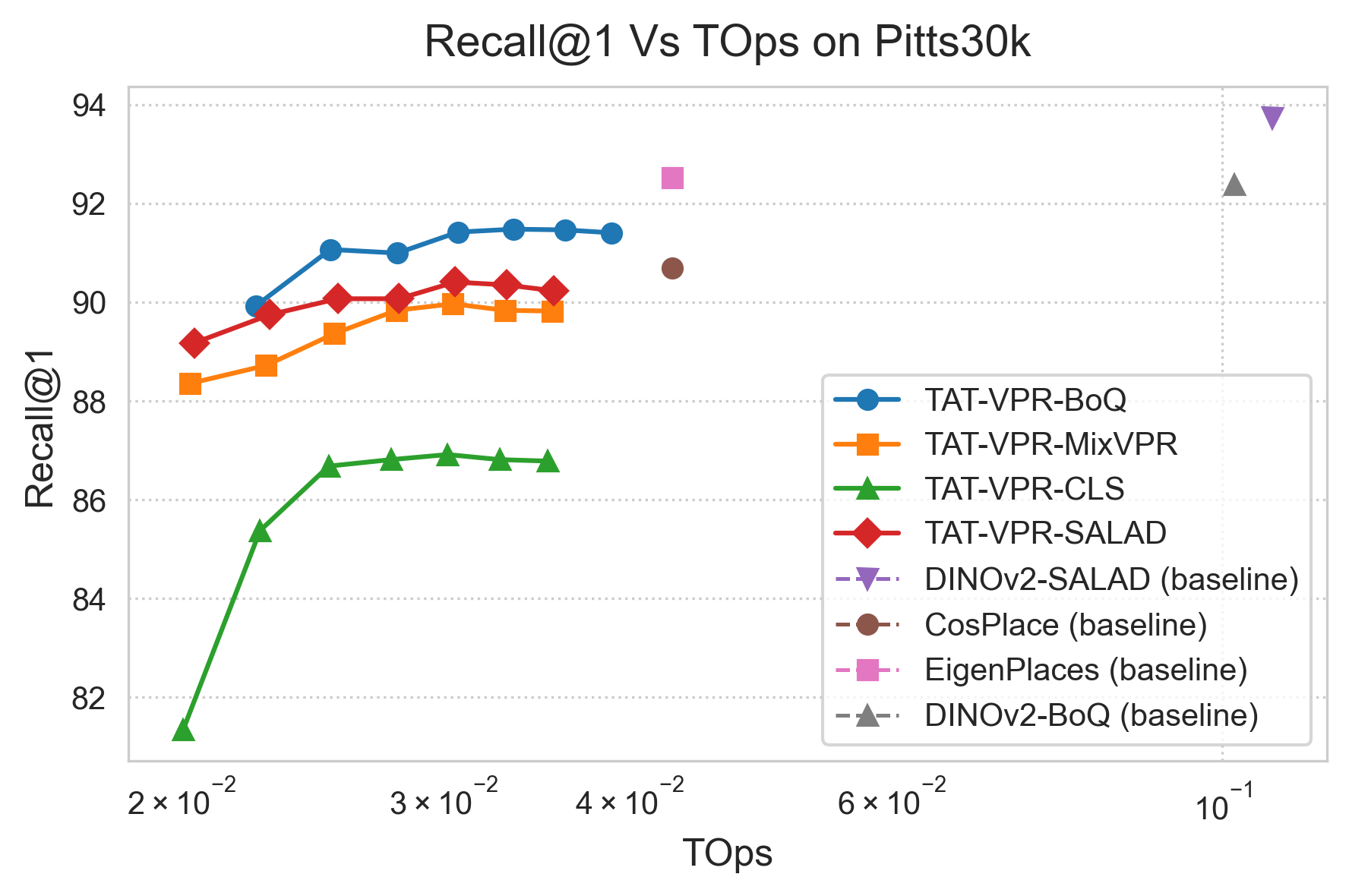
Figure 2. Recall @ 1 versus forward-pass tera-operations. The dashed curve shows TAT-VPR sweeping sparsity from 0 % to 60 %, dominating fixed-cost baselines. :contentReference[oaicite:7]{index=7}
Experimental Highlights
| Dataset | Recall @ 1 Drop | TOps Saved | Model Size |
|---|---|---|---|
| Pitts30k | ≤ 1 % | 40 % | 5 × smaller |
| SVOX (Snow) | 97.0 % | 40 % | 1.7 Recall/MB |
| SVOX (Night) | 61.5 % | 40 % | 1.1 Recall/MB |
TAT-VPR not only preserves accuracy under extreme compression but improves memory-normalised recall (Recall per megabyte) by more than 5× over full-precision ViTs and by 2–3× over convolutional baselines like EigenPlaces. :contentReference[oaicite:8]{index=8}
TL;DR
One model, many budgets.
TAT-VPR shows that you don’t need separate networks for “fast” and “accurate” modes—ternary weights plus adaptive sparsity give a single transformer that you can throttle in real time.
Conclusion
By unifying ternary quantization, activation-level sparsity control and knowledge distillation, TAT-VPR delivers a dynamic VPR backbone ready for on-board SLAM. It cuts memory five-fold, slashes operations by up to 40 %, and still matches state-of-the-art Recall @ 1 on challenging benchmarks. For drones, micro-rovers and any platform where watts and bytes are scarce, TAT-VPR offers a practical path to transformer-level localization. :contentReference[oaicite:9]{index=9}